Created by Little Black Sheep, extra large size
Many people in the industry, including many of my network engineer friends, did not notice that there's a game-changing LLM-specific switch that had been released on the market.

After all, as a staple in networking technology, switches have been evolving for decades. Nowadays, it's challenging for any networking innovation to really grab people's attention and get them excited.
But, this switch really got my attention.
I even think this is probably the best switch in China's AIGC field right now.
Why is it getting such high praise? Let's check it out in the field test, shall we?
This switch, named X400, has 128 400G ports, which seems pretty run-of-the-mill at the first glance.

Because peer companies are pretty much on the same page with this specification (51.2T on a single chip, either 64x800G or 128x400G).

However, this switch, with similar specifications, actually outperforms any of its peer companies.
Compared to the 51.2T solutions proposed by its peer companies, the network consisting of this switch can enhance the LLM training performance by 1.6 times.

The following field test really proves it:
When it comes to an environment of 16,000 GPUs to train GPT3 with 175 billion parameters, the X400 switch cluster outperforms traditional RoCE networks by a mile.
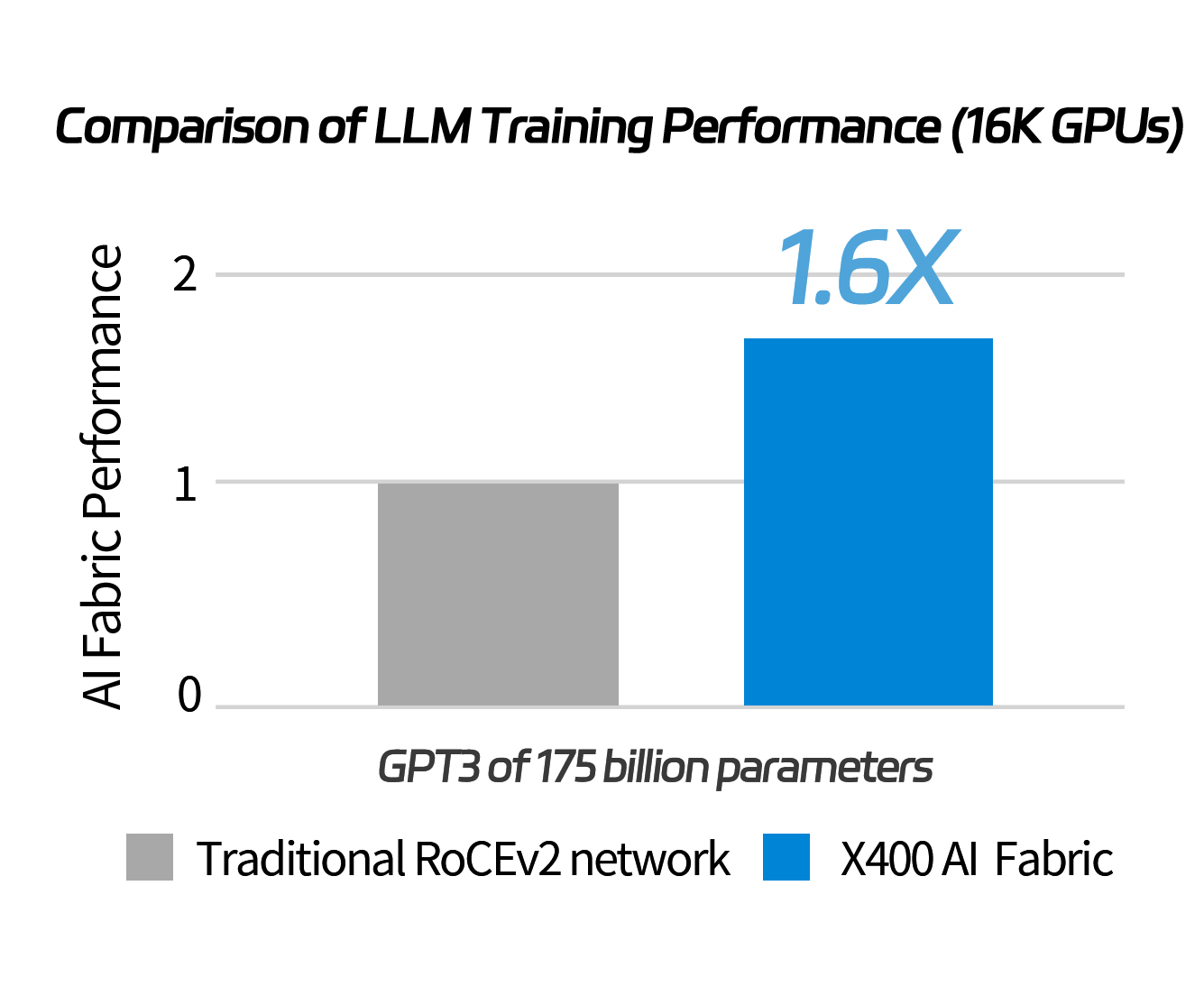
What does that mean?
This means that an Ethernet cluster built on the foundation of X400 switches can rival an InfiniBand network of the same speed in terms of LLM training.
You get the performance of an IB network at the cost of RoCE!

Next, let's talk about why this seemingly ordinary X400 is so impressive.
First and foremost, this is currently the only massively produced switch in China that is based on the NVIDIA Spectrum-4 switch chip.
The current 51.2T switch chip market is dominated by four players: Spectrum-4, Tomahawk 5, Silicon One G200, and Teralynx 10. Each of them brings something unique to the table.
Several major domestic data communication companies and Internet giants have recently rolled out 51.2T switches, most of which are equipped with Tomahawk 5. However, this X400 switch is the first to adopt the NVIDIA Spectrum-4 solution.
As we know, Spectrum-4 is a powerhouse in AI capabilities.

Compared to other solutions, Spectrum-4 boasts some unique advantages tailored specifically for AI business scenarios:
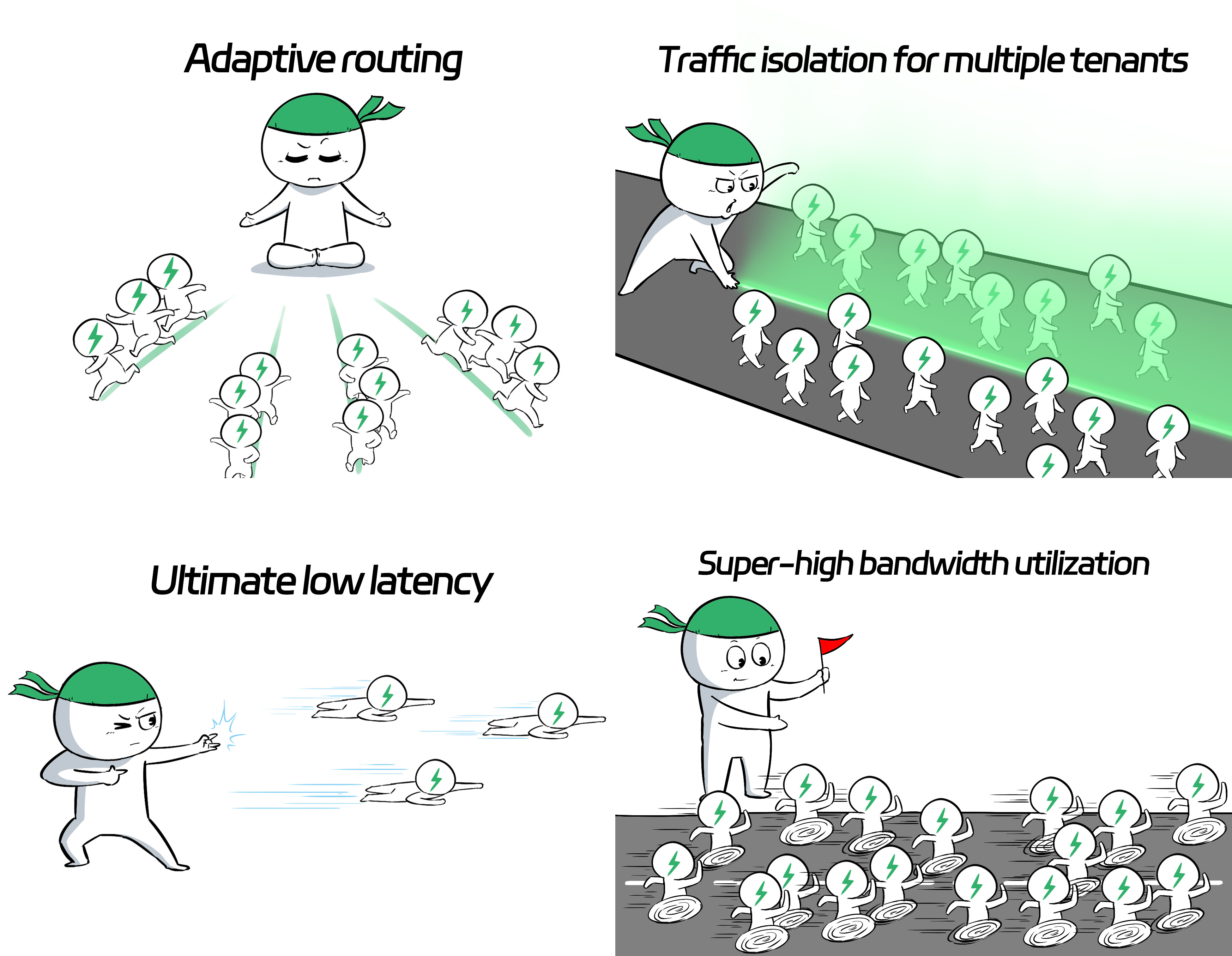
❶ Adaptive routing ensures perfect load balancing. ❷ Traffic isolation for multiple tenants prevents interference. ❸ High utilization of bandwidth in switch links. ❹ Training tasks feature low latency, minimal jitter, and reduced tail latency.
More importantly, most AI LLMs are built on GPUs, and optimizing the network of training clusters heavily relies on support from the Nvidia communication collective library (NCCL).
Just like IB, X400 seamlessly integrates with NCCL without the need for any additional modifications or optimizations as other switching solutions do.

X400 has inborn advantages in terms of hardware, giving it a head start right out of the gate.
However, hardware capability only sets the lower limit for a switch, while the software capability pushes the upper limit.
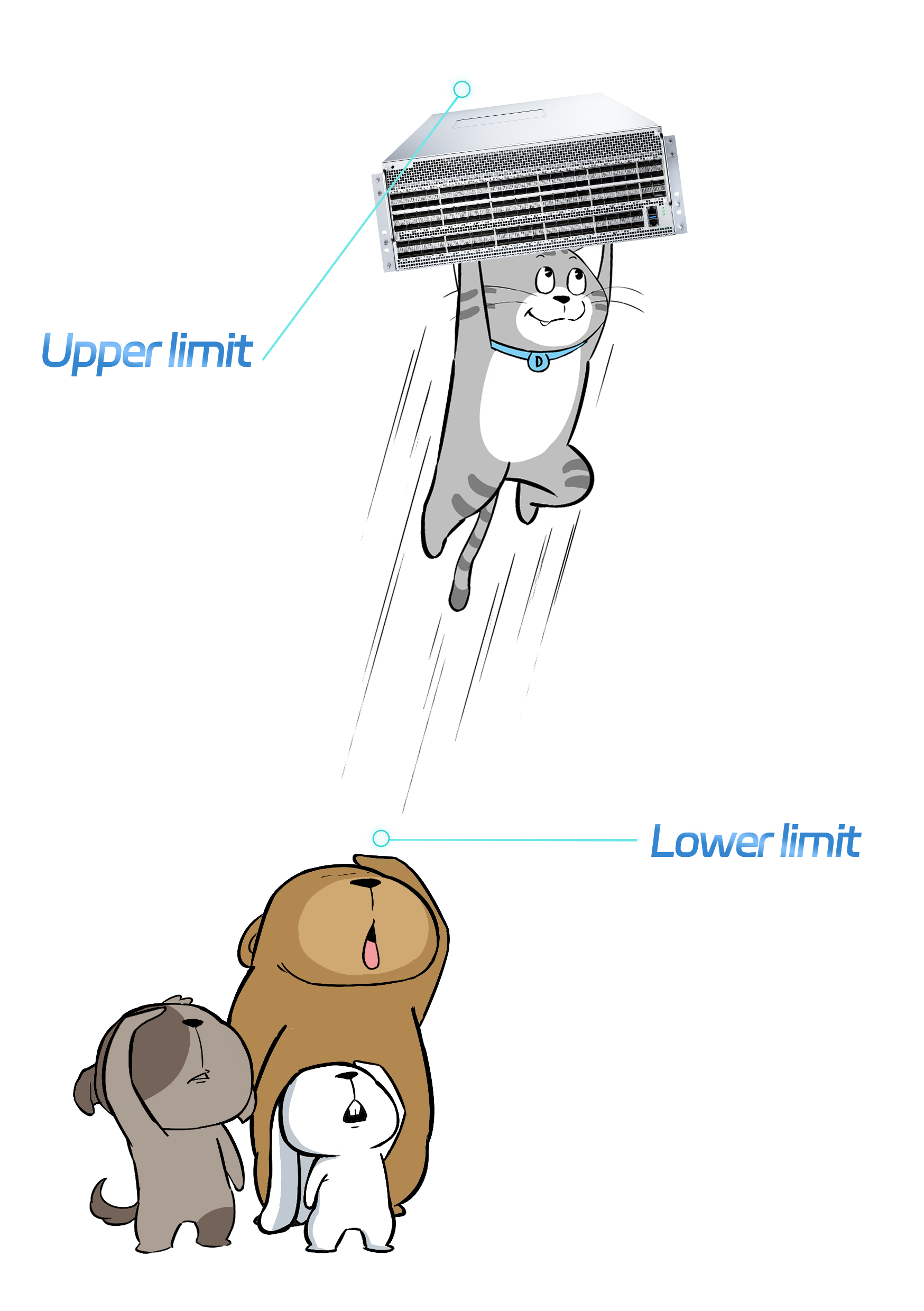
X400 has made special optimization for AIGC scenarios in terms of software.
Let's put it this way. It is software optimization that plays a critical role in making X400 outperform other RoCE switches by a mile.
1. Auto ECN technology
Anyone who's engaged in data center networks knows that in scenarios where network latency and packet loss are critical, ECN technology is typically adopted. The most commonly used one in the market now is called "DCQCN".
ECN (Explicit Congestion Notification) is a network congestion notification and management mechanism. Instead of dropping packets when congestion is detected in the network, ECN adds congestion markings to packets, prompting the sender to dynamically adjust its congestion window (CWND) to prevent congestion from occurring.
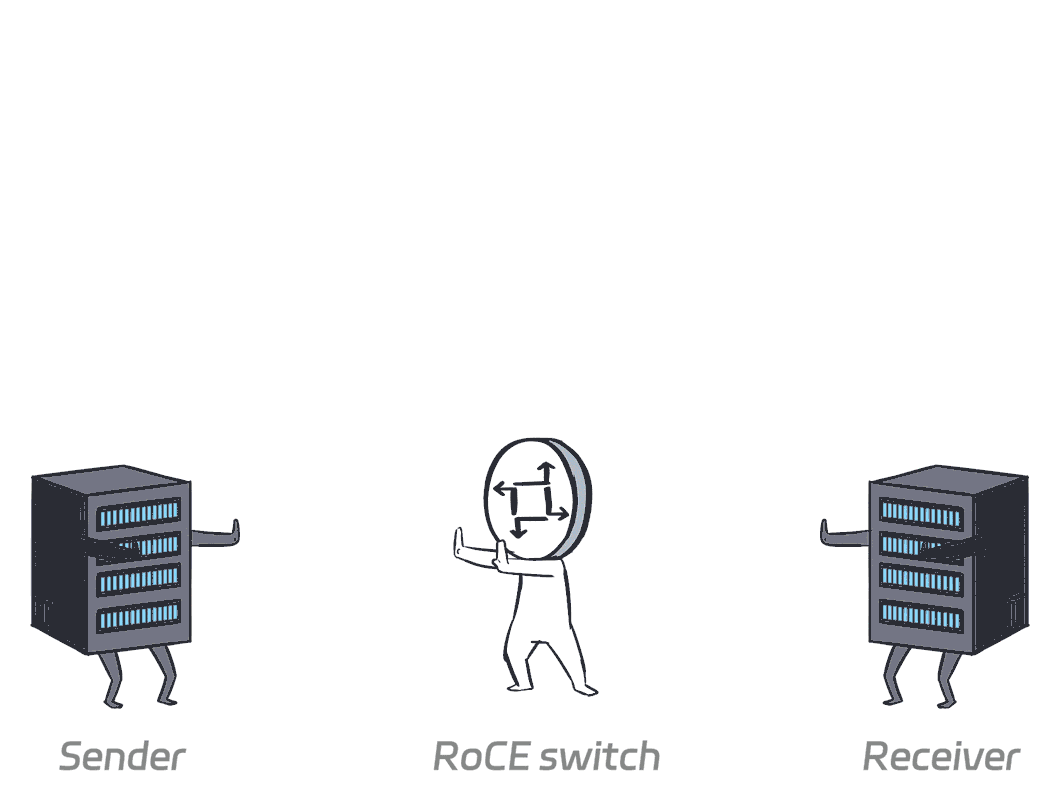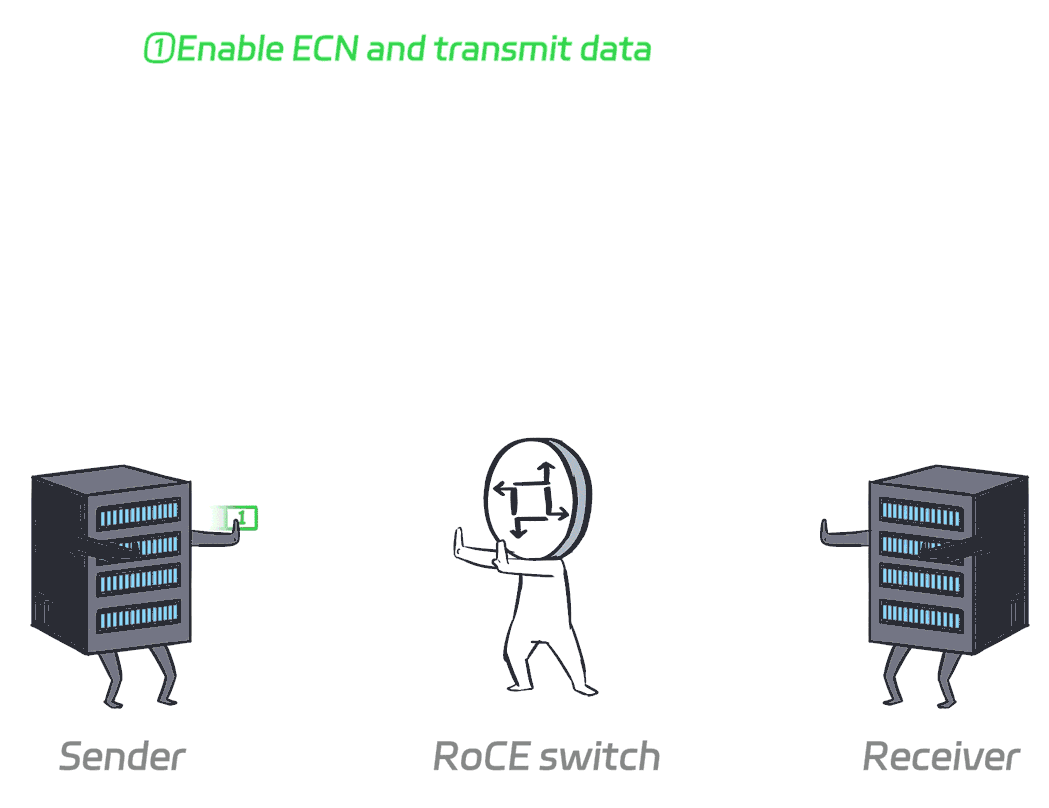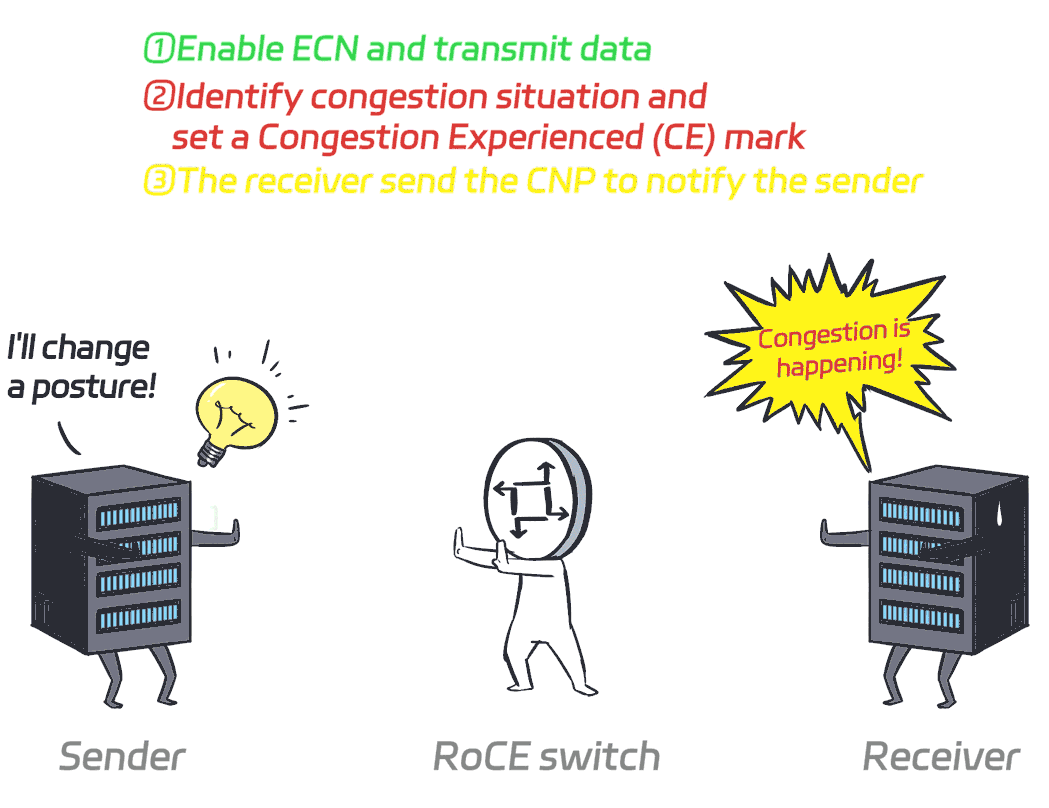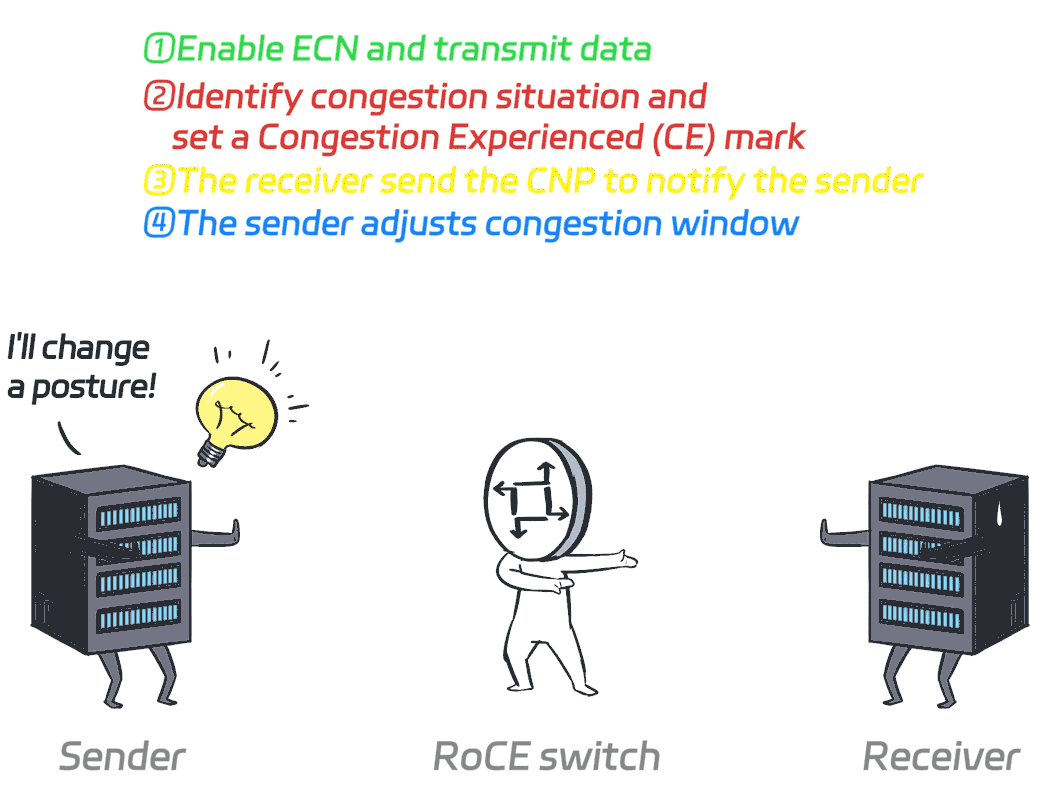
To put it simply, it just tells the sender to take smaller steps when things are about to get congested, and take bigger steps when there's no congestion.

However, choosing the size of this "step" (congestion window) is quite tricky. If the window is too big, it can mess things up, but if it's too small, it will affect the throughput.
Finding the optimal "window size" dynamically to strike a balance between avoiding congestion and maximizing throughput is a major challenge for many network engineers in the data center.
Manually optimizing an ECN is such a hassle. How does the X400 switch do it?
This thing is smart. It's tackling AI problems with AI itself. So, it came up with an algorithm called AutoECN, which is like having a tuned AI model built into each switch.

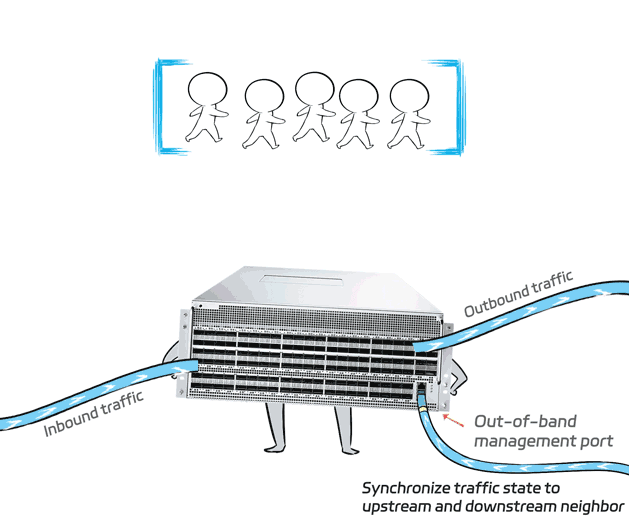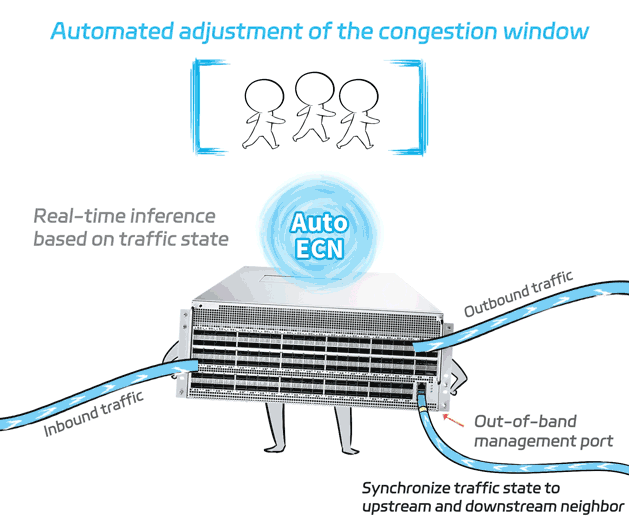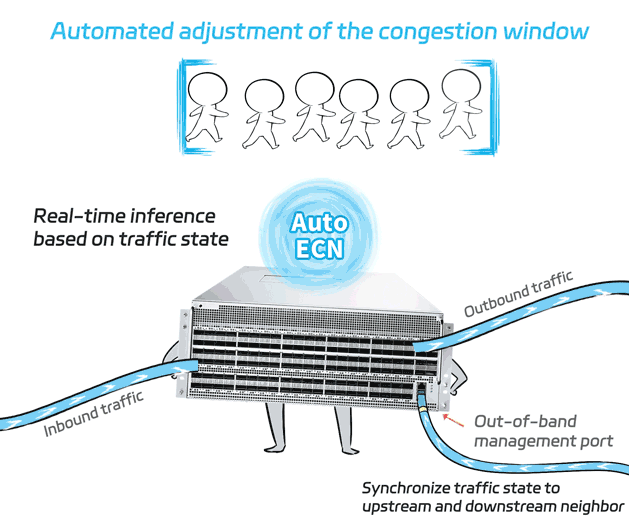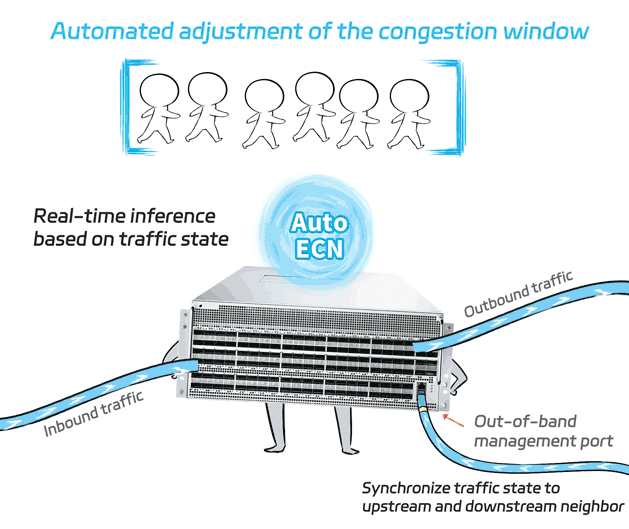
The X400 switch will capture traffic state in real-time and synchronize it to upstream and downstream neighbor through out-of-band port (so this synchronization won't consume any in-band bandwidth).
The collected traffic state is fed into the built-in AutoECN AI model of the switch. The model then performs real-time inference based on the inputs to determine the optimal ECN parameters at that moment, which are then set in real time.
Compared to the traditional static ECN setting, AutoECN can dynamically adjust the ecn parameter to the optimal value. Also, it is not vulnerable to rate adjust failure caused by delayed CNP message.
Come check out the real-life results below!
The same set of traffic is being transmitted on the switches equipped with static ECN and AutoECN respectively. The latter features a significant improvement in FCT(flow complete time) efficiency.
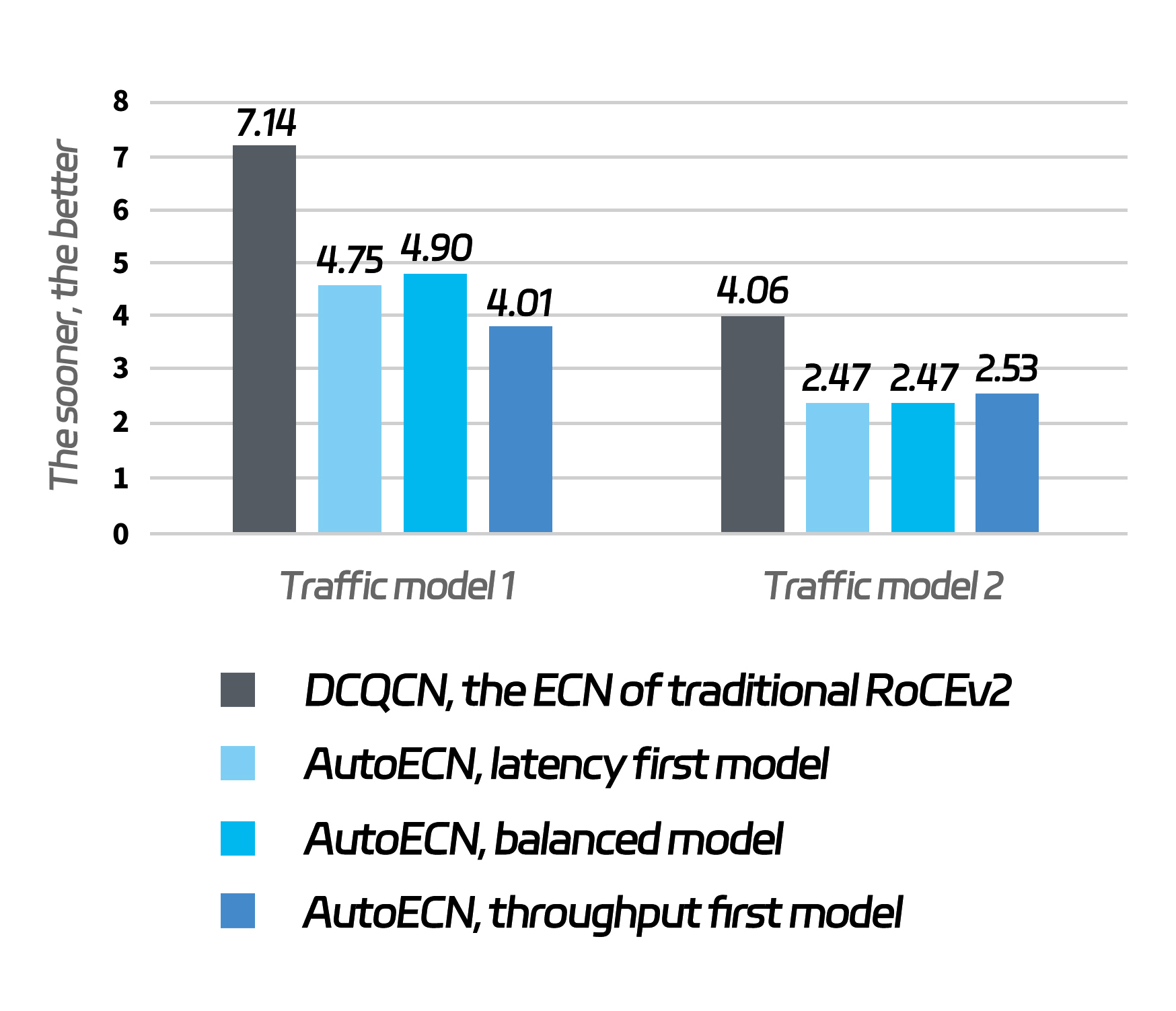
AutoECN offers three different models, as shown above: latency first, throughput first, and balanced model. Each is trained with different super parameter. Then, we ran tests with the traffic with each of the two features. Both models significantly outperformed the traditional ECN (the shorter the time taken to transmit each set of traffic, the better).
When your business is latency-critical, choose the latency-first model; if throughput-critical, choose the throughput first model; if you want them both, choose the balanced model.
No matter how unpredictable the traffic is, AutoECN always comes up with the optimal solution by dynamically adjusting parameters based on AI technology.

2. RTT-CC Congestion Control
If your business is particularly sensitive to network latency and desires lower latency and jitter, the AI Fabric solution built on the X400 switch offers an additional ace up its sleeve: RTT-CC.
RTT-CC doesn't require explicit notification of congested packets like ECN does. Instead, it predicts network congestion by continuously monitoring and evaluating the round-trip times of packets.
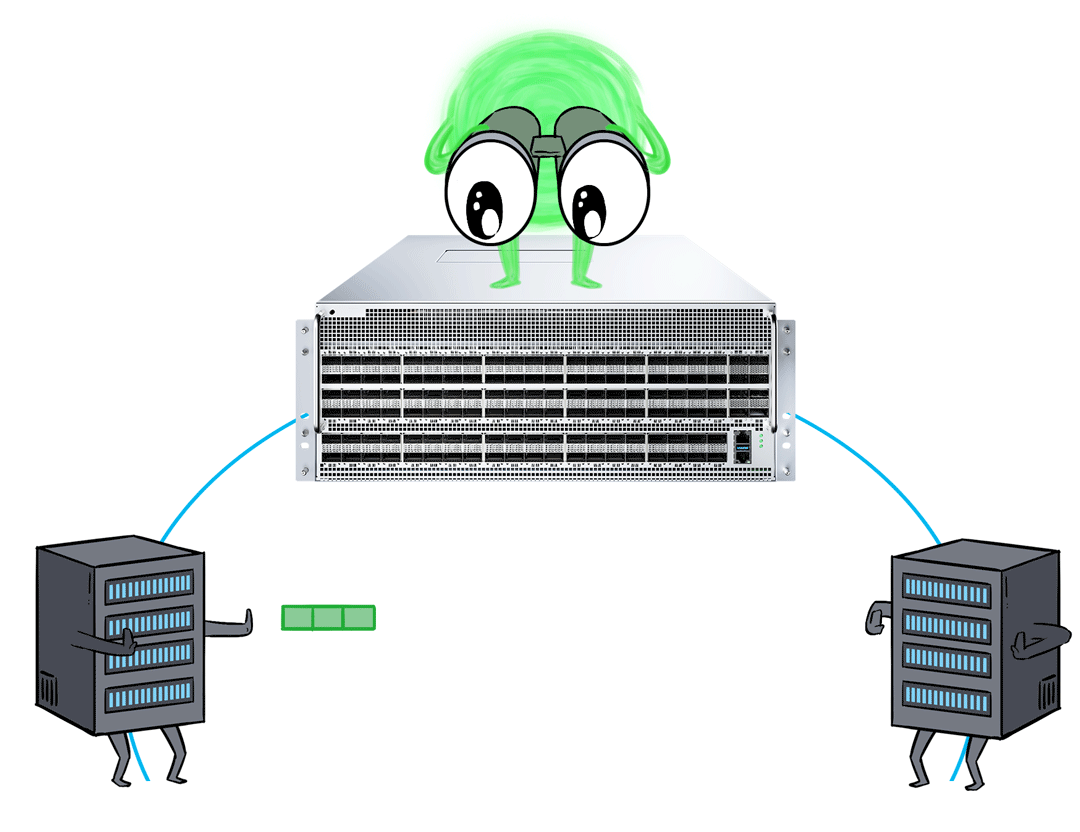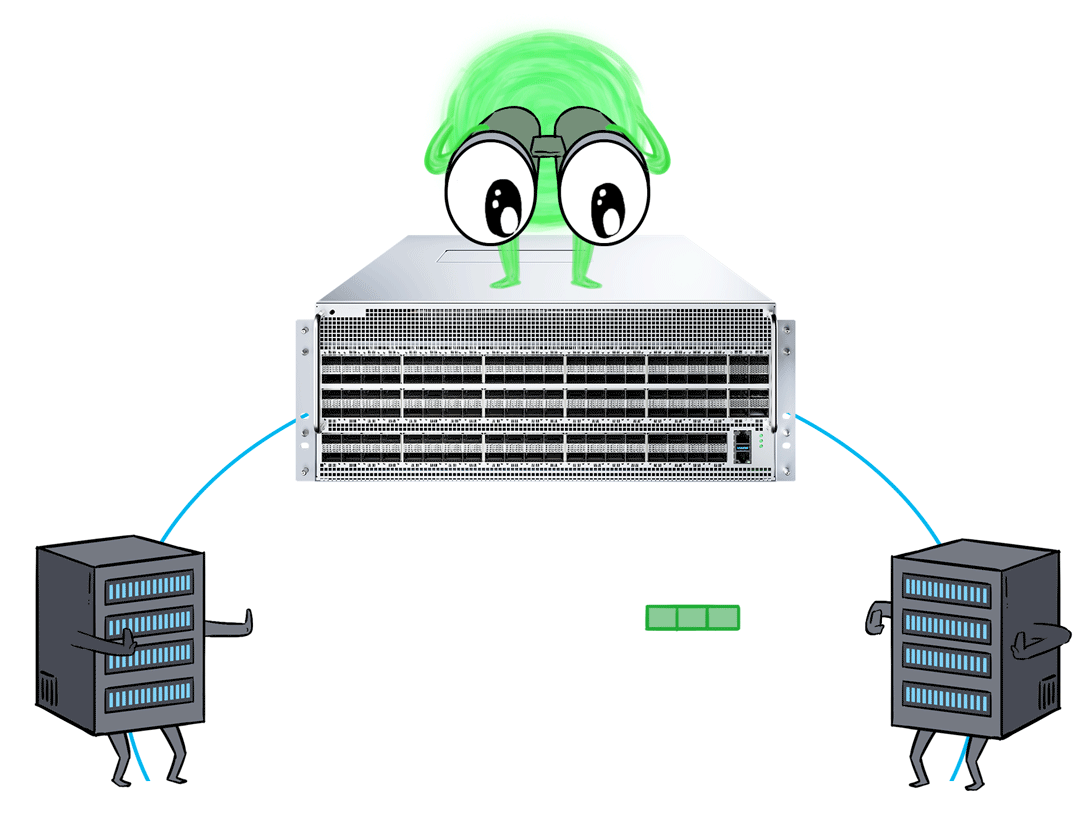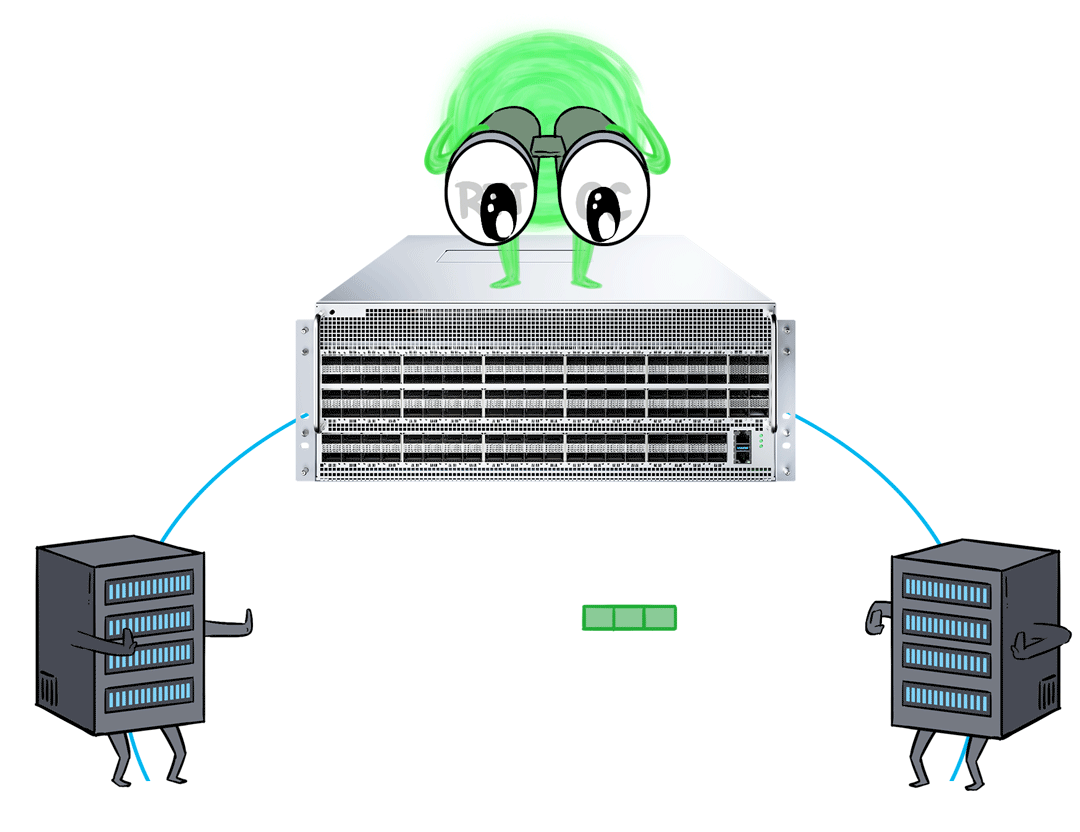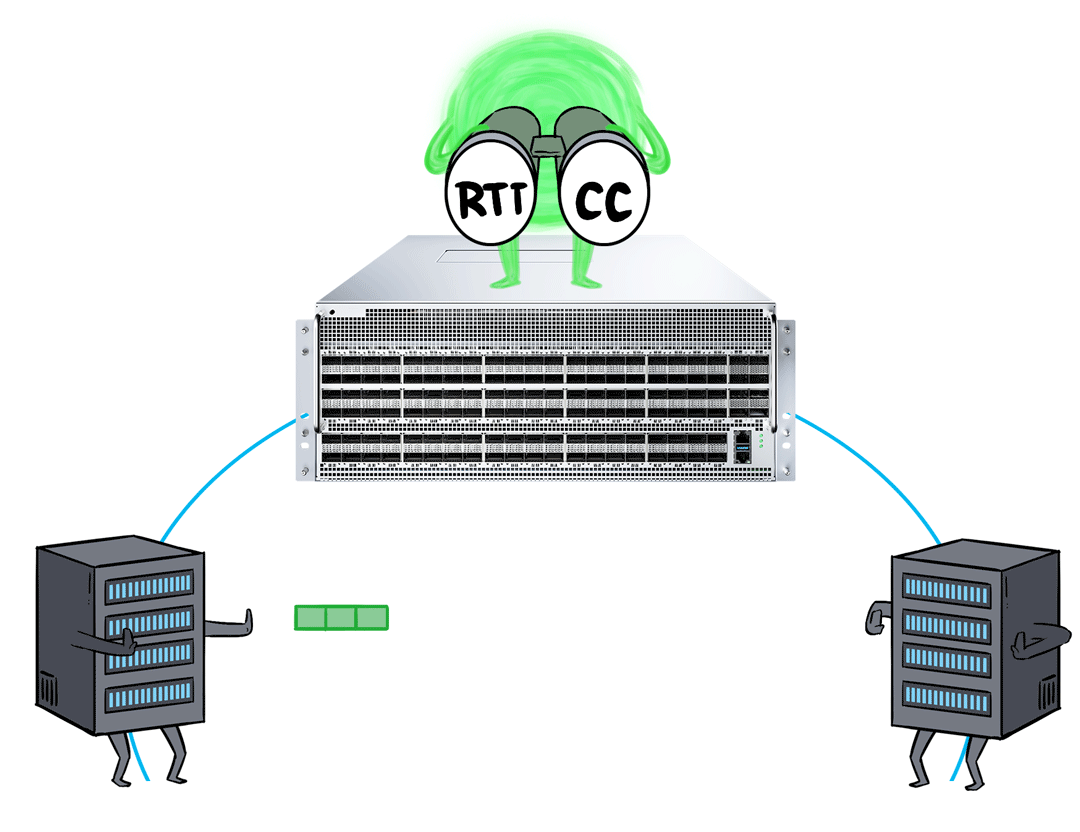
The RTT-CC feature of the X400 AI Fabric solution utilizes a hardware-based feedback loop, which dynamically monitors congestion and adjusts the size and rate of the send window in real-time for improved performance and superior latency.
In this way, having congestion control technologies like RTT-CC and AutoECN at the same time can better meet the demanding requirements of low latency, high throughput, and zero packet loss in challenging scenarios.

3. Load balancing on a per-packet basis
In data center networking, when it comes to multipath transmission, traditional RoCE solutions typically leverage ECMP and other techniques to achieve load balancing across multiple links.
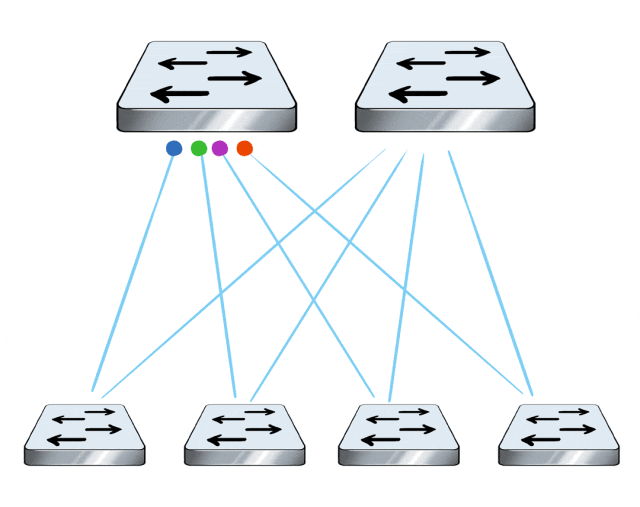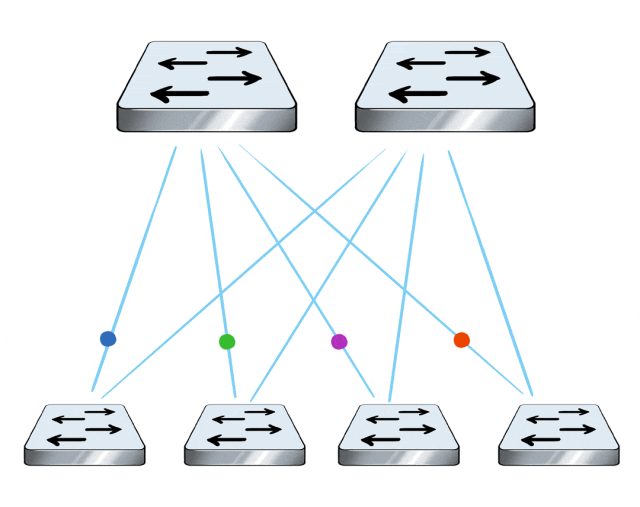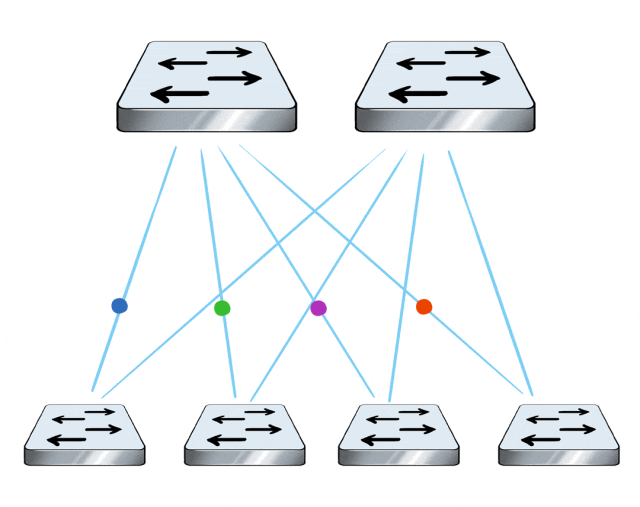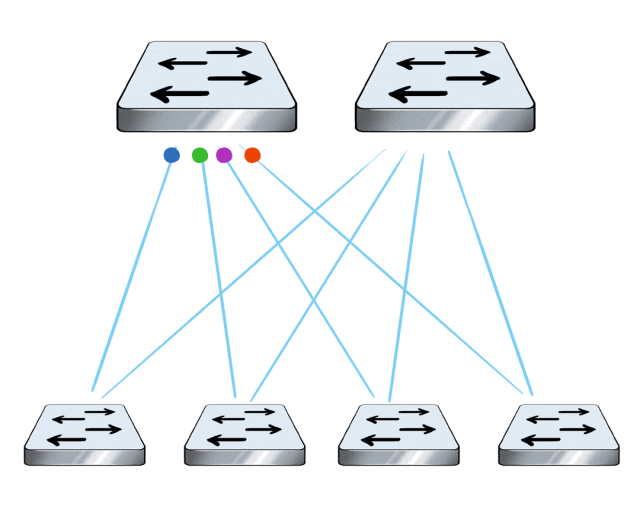
However, the load balancing of ECMP is flow-based, meaning that each flow is scheduled to different links based on its hash value. Therefore, the granularity is too coarse.
In extreme cases when the hashing is uneven or there is a significant disparity in flow sizes, it can lead to all traffic being routed to one link, leaving the other links idle and causing a drop in overall network transmission efficiency.
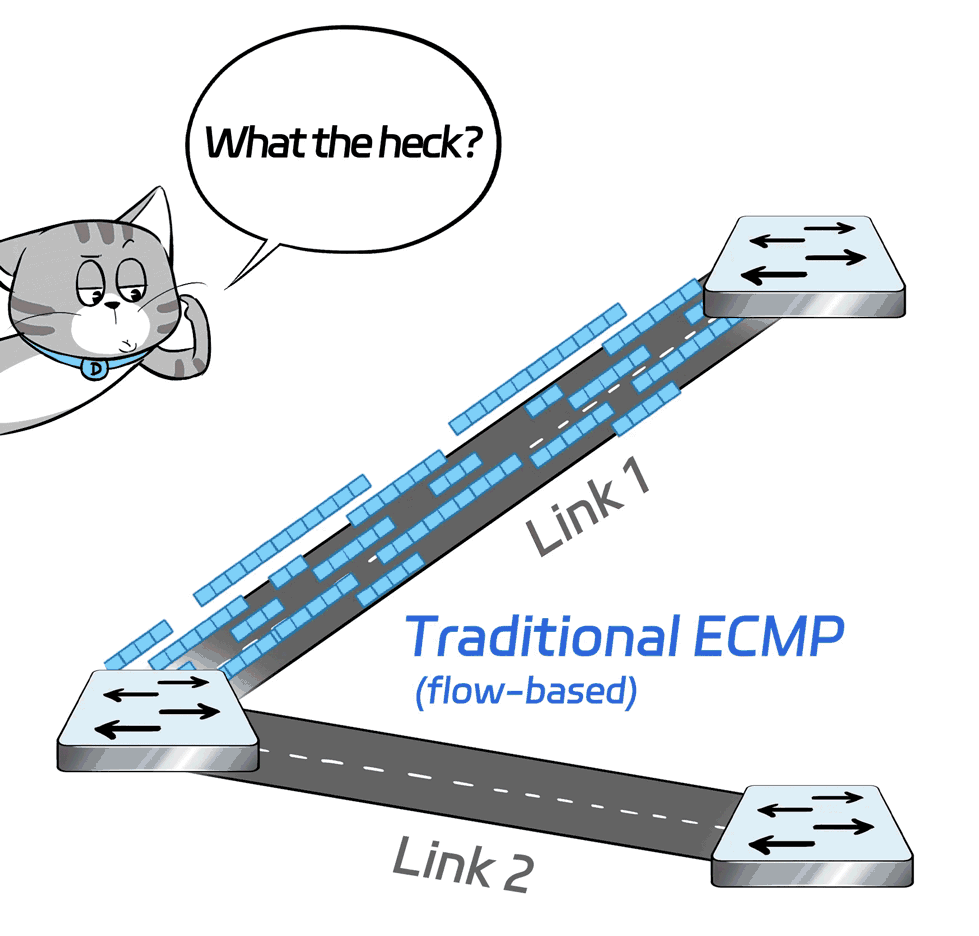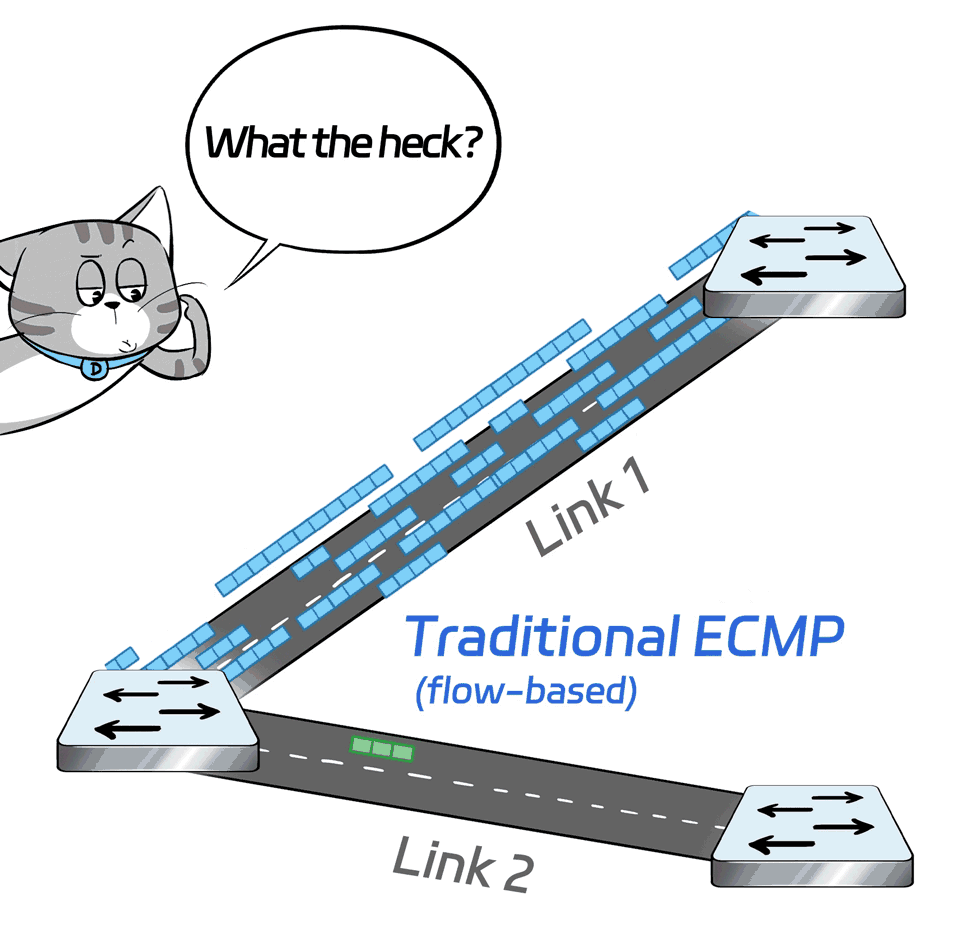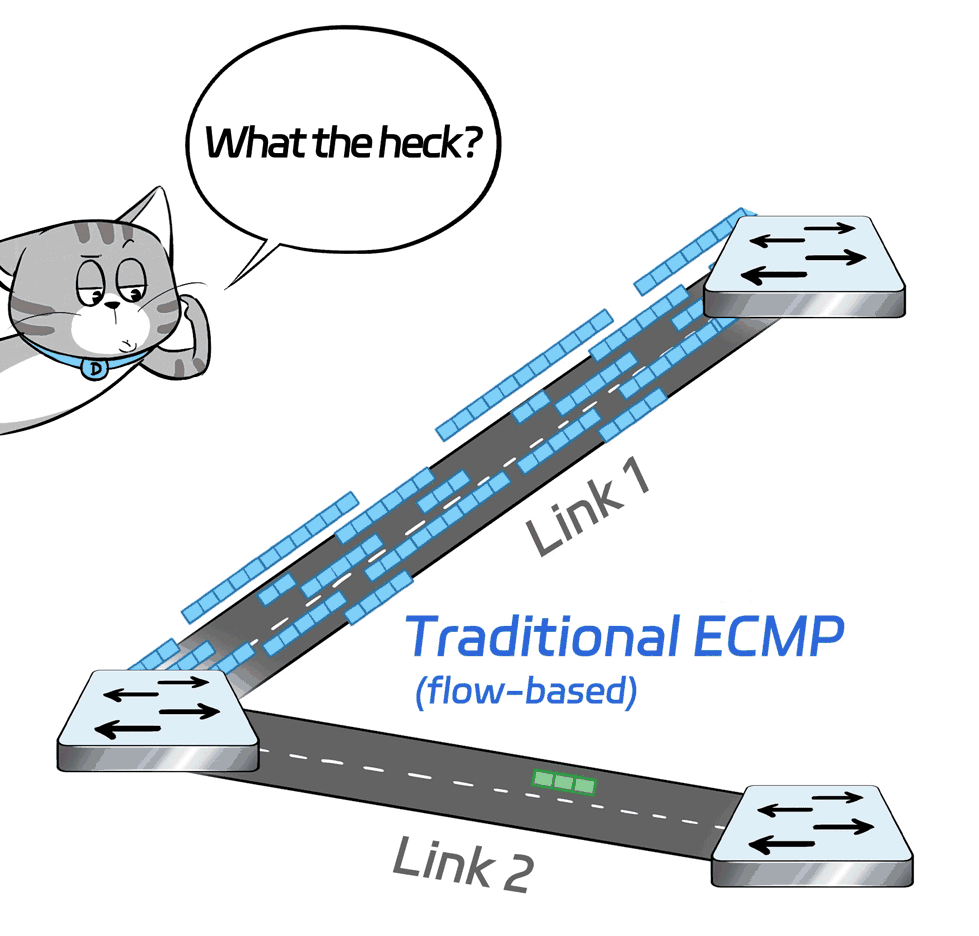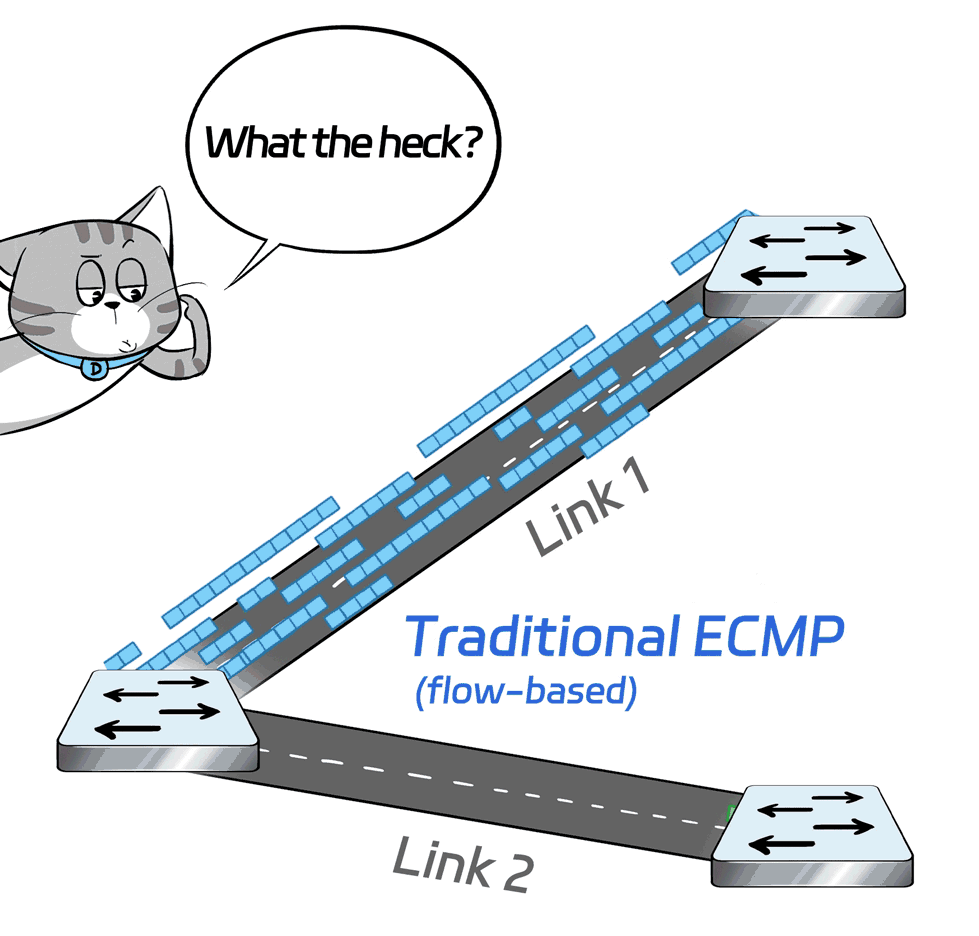
What's the solution?
The X400 switch supports adaptive routing (AR) and packet spraying technologies.
Simply put, it's load balancing on a per-packet basis: The scheduling is based on each individual data packet, so the granularity is finer and the algorithm is better.
In this way, the load is evenly distributed on each link, boosting the overall network throughput, maximizing the capacity of each link, and fully utilizing every GPU.
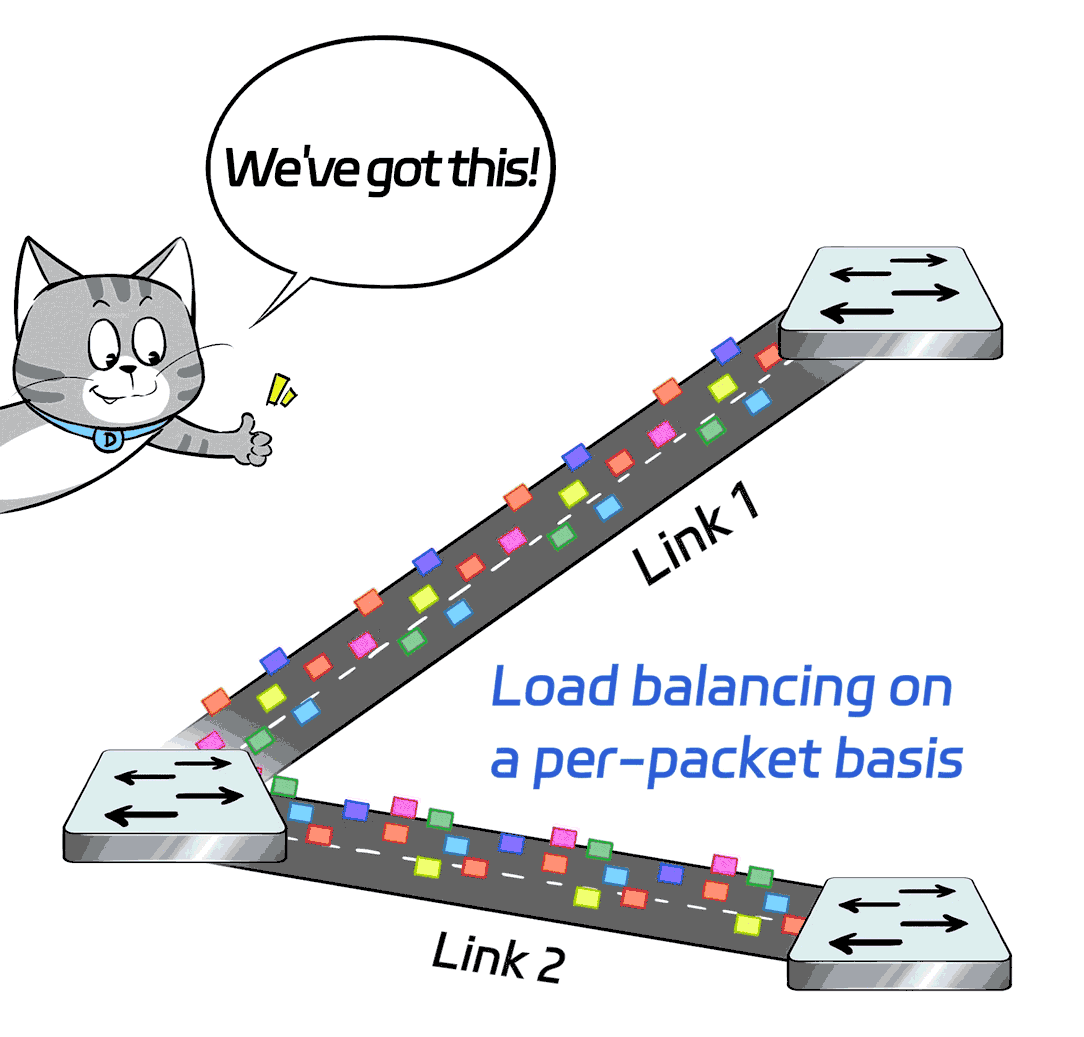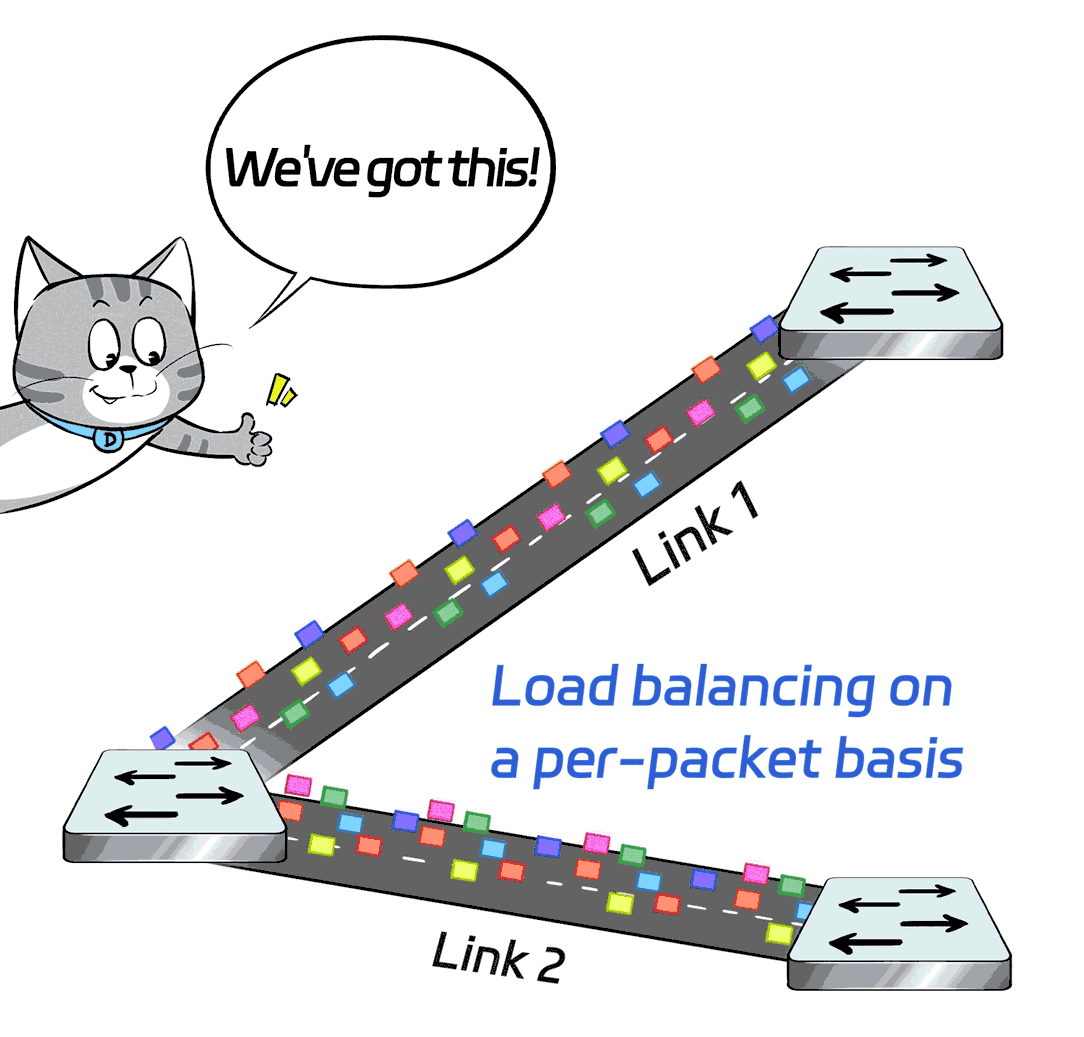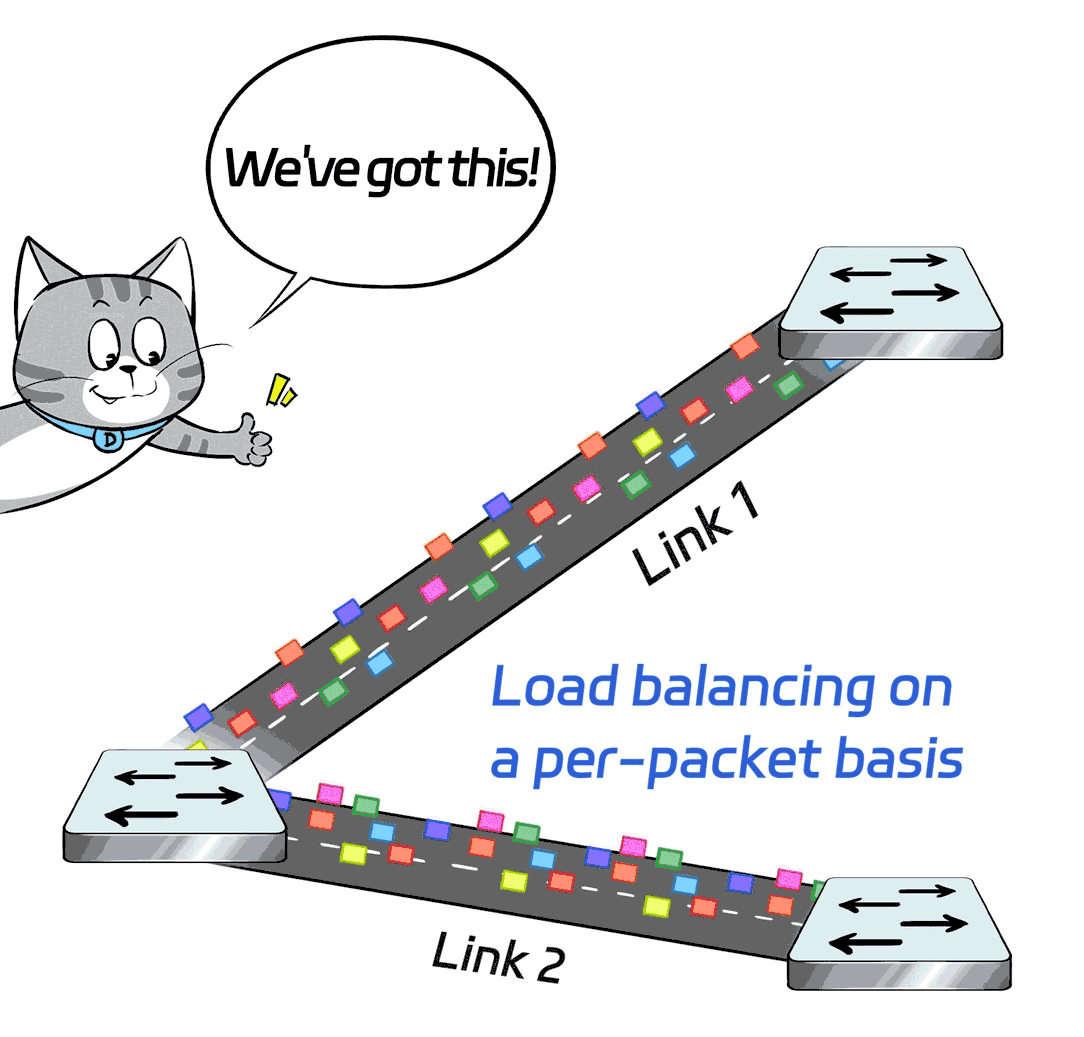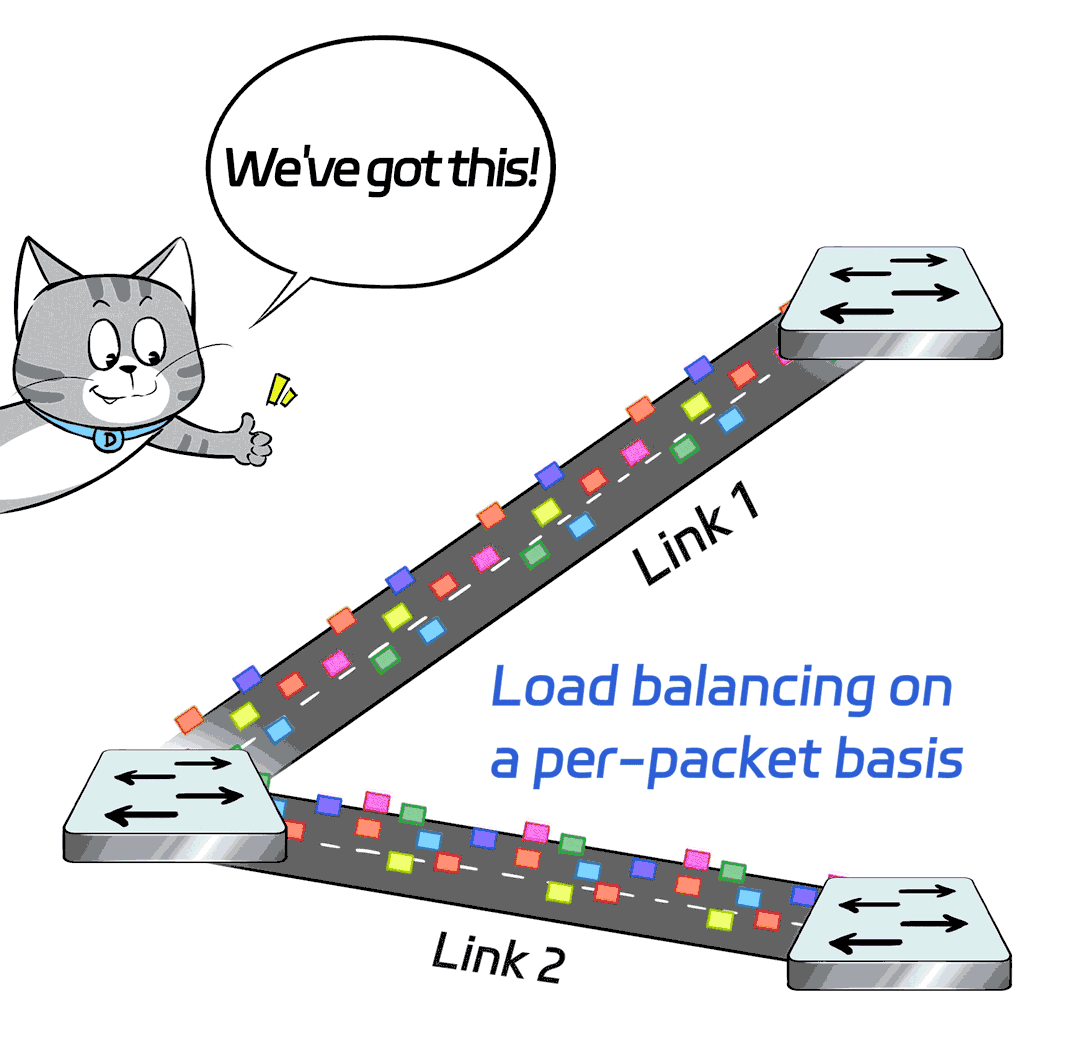
Of course, this per-packet load balancing can be tricky because each packet may take a different route, leading to possible data packet reordering by the time they reach the server. Without some special skills, the server may struggle to keep up.
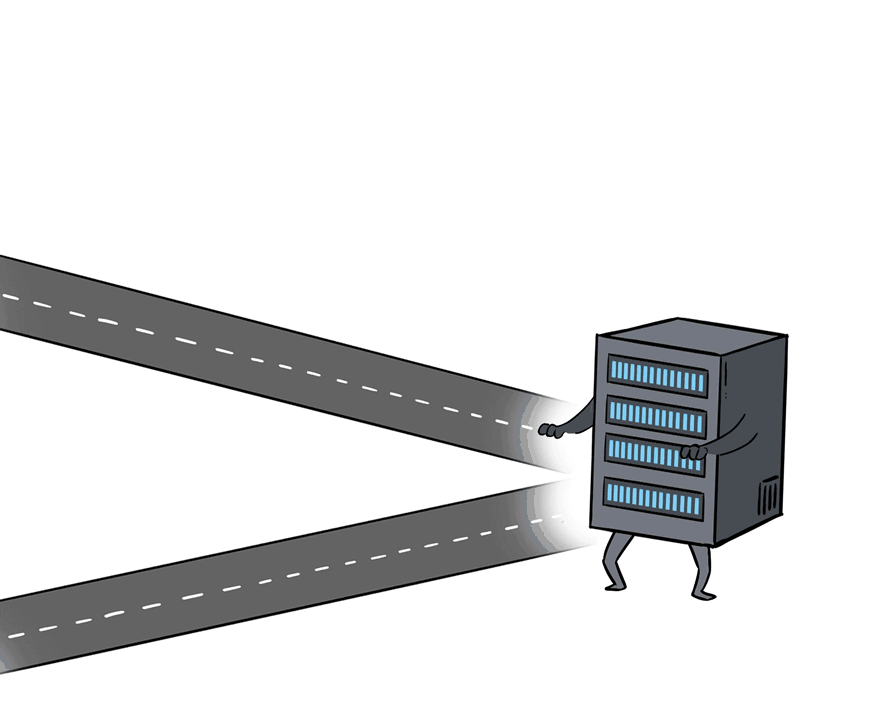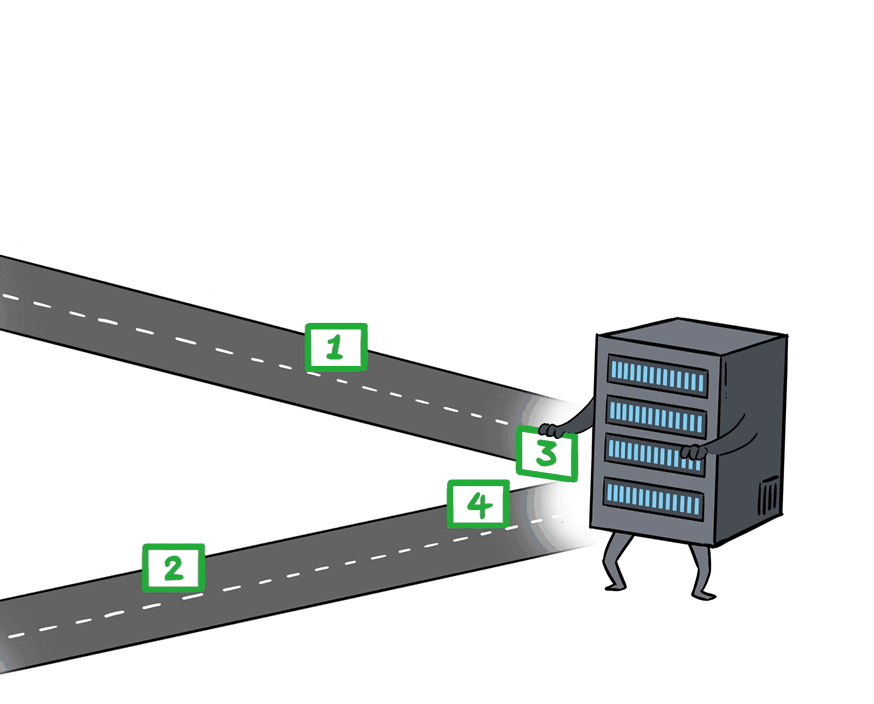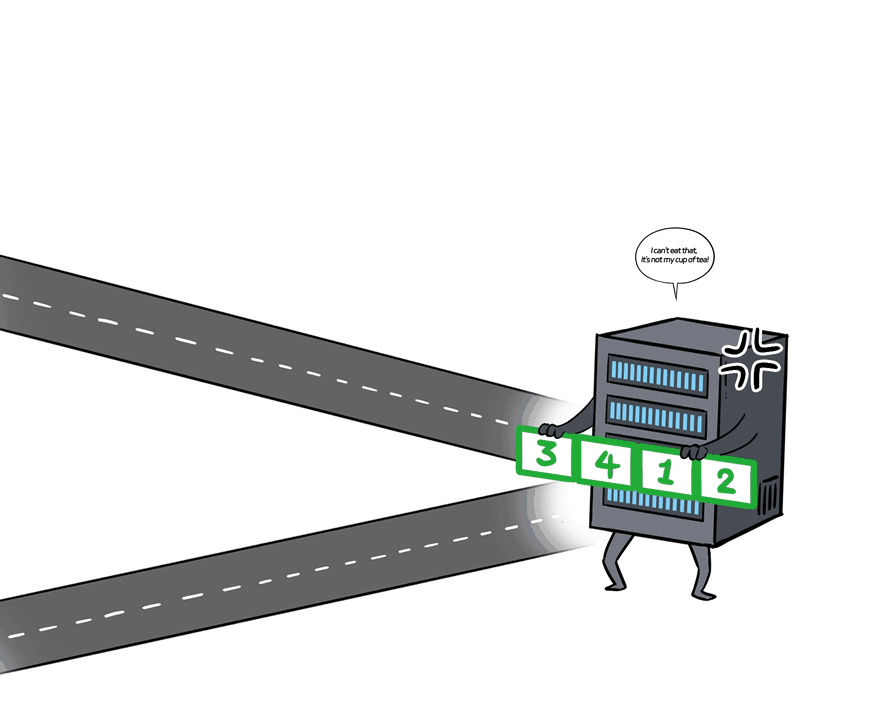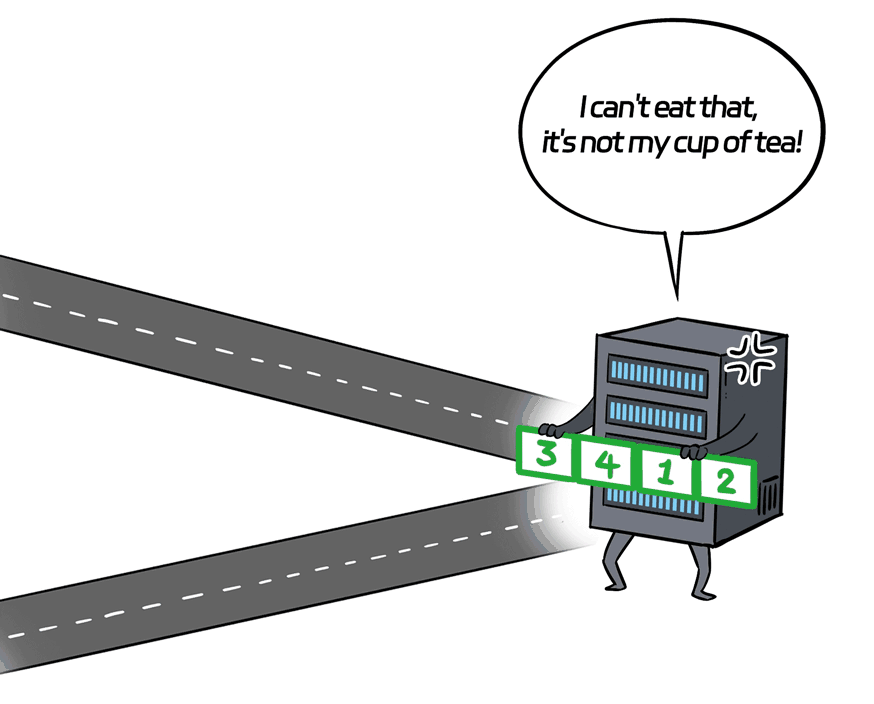
So, the servers that come with the X400 switch are also equipped with smart NICs that support order preservation, allowing them to rearrange out-of-order data packets.
This is perfect. We don't need to worry about disordering anymore and it ensures the efficient use of links.
With these three superpowers (AutoECN, RTT-CC, adaptive routing), the X400 switch has managed to handle the demanding requirements of the tens of thousands or even hundreds of thousands of GPUs at intelligent computing centers.

Moreover, the X400 switch incorporates a plethora of technologies at the software level to enhance reliability and maintainability.
For example, features like fault self-recovery, IGE intelligent protection, visual monitoring, and ZTP deployment...

Also, the X400 switch complies with the S3IP-UNP specifications and is designed to support open-source SONiC and third-party network operating systems, providing great flexibility for customers looking to build large-scale computing clusters.

After all those introductions, whose product is this X400 switch, anyway?
That's IEIT SYSTEMS.
At the 2024 IPF, IEIT SYSTEMS officially unveiled the X400 Super AI Ethernet Switch specially designed for generative AI scenarios.

IEIT SYSTEMS offers a plug-and-play X400 AI Fabric solution for terminal-network collaboration, supporting massive clusters with up to 512K GPUs.
Compared to traditional RoCE networking in the industry, X400 boasts a bandwidth utilization rate of over 95%, reduces latency by 30%, and significantly boosts the speed of LLM training.

How come IEIT SYSTEMS is able to an AI switch with such incredible performance? It even outcompetes the RoCE products of data communication giants.
IEIT SYSTEMS is a leading AI server provider in China, securing the No.1 position for 7 consecutive years.
As a core provider of network services for top Internet clients, IEIT SYSTEMS has extensive experience in building networks for data centers and intelligent computing centers.

Based on a deep understanding of AI infrastructure and applications, as well as committed R&D efforts in networking, IEIT SYSTEMS has unveiled the X400 Super AI Ethernet Switch, making it an eye-catching product in the industry.

Everything is being reshaped in the era of large language models while IEIT SYSTEMS X400 is building a fast track to LLM dominance!
